
A day in the life of an Optimizely OMVP - Creating an AI powered conversational robot that utilises Semantic Search in Optimizely Graph
Overview
Hello and welcome to another installment of A Day In The Life Of An Optimizely Developer!
In this blog post I will be covering an exciting POC that I recently undertook for one of our clients. The ask was to create a POC of an AI powered chatbot that followed the RAG model utilising Optimizely Graph and Semantic Search for retrieving related content that the chatbot can use as a context to be able to enhance the quality and relevance of its generated responses.
What is RAG?
The term RAG stands for Retrieval-Augmented Generation model and is a type of architecture used in natural language processing (NLP) and machine learning.
In simple terms:
-
Retrieval:
- This part involves fetching information from a pre-existing set of data or knowledge. It might retrieve relevant text passages or documents based on a given input or query.
-
Augmented Generation:
- The system then uses this retrieved information to enhance or "augment" its ability to generate new, contextually relevant content. This content can be in the form of text, responses, or any other linguistic output.
In the context of language models, this combination is often employed to improve the model's ability to generate more accurate and contextually appropriate responses by leveraging information from a broader knowledge base.
For instance, if you ask a question, the model might retrieve relevant information from a database or existing text and use that information to generate a more informed and accurate response. This approach aims to enhance the overall performance of the system by leveraging both pre-existing knowledge and the model's generative capabilities.
Process Flow
The following is a high-level overview of the process flow from the moment the user enters a search query.

- Users enters prompt.
- Prompt used to search website (Semantic search within Optimizely Graph used for this).
- Content components extracted from the returned search data.
- Embeddings created from the content components, these are saved to a persistent data source.
- Prompt created and context created containing embeddings, these are fed into LLM with a strong anti-hallucination bias.
- Show answer generated by LLM with links to citations.
Semantic Search within Optimizely Graph
Semantic search is an advanced search technique that goes beyond traditional keyword-based search to understand the meaning of words and the context in which they are used. Instead of simply matching search queries with keywords, semantic search aims to comprehend the intent and the context of the user's query to provide more accurate and relevant results.
To be able to perform semantic searches within Optimizely Graph, a number of pre-requisite steps need to be carried out to enable Graph.
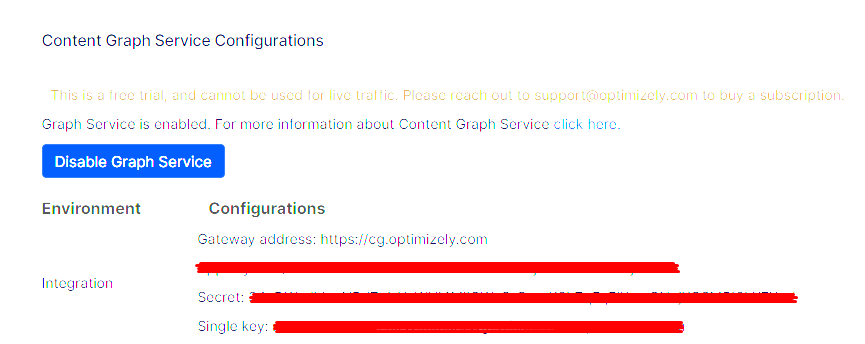
- Enable the Graph service within PaaSPortal - when you enable the service be aware that although you have enabled a free trial, it cannot be used for live traffic and a subscription needs to be purchased when using in a production environment.
- The next step is to install
Optimizely.ContentGraph.CMSin your Optimizely Content Management System (CMS) site to synchronize content types and content. In Visual Studio, go to Tools > Nuget Package Manager > Package Manager Console. At the console, enterinstall-package Optimizely.ContentGraph.Cms. - You now need to add some new configuration to your appsettings.json file:
"Optimizely": { "ContentGraph": { "GatewayAddress": "", "AppKey": "", "Secret": "", "SingleKey": "", "AllowSendingLog": "true" } }
GatewayAddress– URL for the API Gateway. This value should be set tohttps://cg.optimizely.comfor all production environments.AppKey– Available via the Content Graph Service Configurations area of PaaSPortalSecret– Available via the Content Graph Service Configurations area of PaaSPortalSingleKey– Available via the Content Graph Service Configurations area of PaaSPortalAllowSendingLog– Flag that allows sending errors and warnings to the API Gateway. This data helps the support team investigate when something goes wrong. Defaults totrue.
- Next, if you do not use Content Delivery API in your CMS site yet, add the following in the
ConfigureServices(IServiceCollection services)method ofStartup.cs. Optimizely Graph depends on Content Delivery API, this is the minimum configuration.
services.ConfigureContentApiOptions(o => { o.IncludeInternalContentRoots = true; o.IncludeSiteHosts = true; //o.EnablePreviewFeatures = true;// optional }); services.AddContentDeliveryApi(); // required, for further configurations, see https://docs.developers.optimizely.com/content-cloud/v1.5.0-content-delivery-api/docs/configuration services.AddContentGraph(); //the following is obsolete and is kept for compatibility for now //services.AddContentGraph(_configuration); - The final step is to enable synchronisation, there are two types of synchronisation available, the first is event-driven synchronisation, by default The GraphQL schema stays up-to-date with changes to your site anytime someone edits a content type or one of its properties. The job also synchronizes content to the service any time content is created, updated, or deleted. The second type of synchronisation is via a scheduled job called "Optimizely Content Graph Synchronisation", normally this would only be run if you have an existing site with pre-existing content that needs to be synchronised.
Now that you have Graph enabled andf content synchronised you are now in a position to start doing semantic searches. You can easily perform semantic searches by changing the value of _ranking in the OrderBy to SEMANTIC (by default the _ranking field is set to RELEVANCE). In the query shown below, we are performing a semantic search for SitePageData content types where the _fulltext field contains the 'search query' specified in the $searchQuery parameter. The data returned is the total number of matching items, and then for each item the name and _fulltext field contents are returned.
query SemanticSearch($searchQuery: String)
{
SitePageData(
orderBy: { _ranking: SEMANTIC }
where: { _fulltext: { contains: $searchQuery }})
{
total
items {
Name
_fulltext
}
}
}An example of how the data is retured is shown below:
{
"data": {
"SitePageData": {
"total": 2,
"items": [
{
"Name": "Lorem ipsum dolores sit amet.",
"_fulltext": [
"Lorem ipsum dolores sit amet.",
"<p><strong>Lorem ipsum dolor</strong><em> sit amet consectetur</em> <span style=\"text-decoration: underline;\">adipiscing</span>, <sup>elit</sup> <sub>sollicitudin</sub></p>\n<p>vivamus congue gravida nunc semper, justo imperdiet interdum litora at. Faucibus integer porttitor odio lacus libero id habitasse vel, mollis fermentum luctus diam parturient eros orci hendrerit, per metus sodales magnis placerat varius lectus. Ultrices scelerisque etiam dapibus in, tincidunt non.</p>"
]
},
{
"Name": "Fly me home, kid",
"_fulltext": [
"Fly me home, kid.",
"<p>Kid, I've flown from one side of this galaxy to the other. I've seen a lot of strange stuff, but I've never seen anything to make me believe there's one all-powerful Force controlling everything. There's no mystical energy field that controls my destiny. It's all a lot of simple tricks and nonsense. I'm surprised you had the courage to take the responsibility yourself.</p>"
]
}
}
}
}The full code snippet for performing a semantic search against Graph in C# is shown below. This is utilising a NuGet package called GraphQL.Client and to ensure that content is serialized correctly you also need to install the related NuGet package called GraphQL.Client.Serializer.Newtonsoft.
public async Task<GraphQLResponse<Rootobject>> PerformSemanticSearch(GetChatbotQuery query)
{
// Create the GraphQL query using a variable for the search query
var contentRequest = new GraphQLRequest
{
Query = """
query SemanticSearch($searchQuery: String)
{
SitePageData(
orderBy: { _ranking: SEMANTIC }
where: { _fulltext: { contains: $searchQuery }})
{
total
items {
Name
_fulltext
}
}
}
""",
OperationName = "SemanticSearch",
Variables = new
{
searchQuery = query.Query
}
};
// Create an instance of the GraphQL client - endpoint hard-coded for this POC
var graphQlClient = new GraphQLHttpClient("https://cg.optimizely.com/content/v2?auth=<simplekey>", new NewtonsoftJsonSerializer());
// The response returned from the GraphQL query
var graphQlResponse = await graphQlClient.SendQueryAsync<Rootobject>(contentRequest, new CancellationToken());
return graphQlResponse;
}OpenAI
The next step in the process is to utilise whichever LLM you wish to use, this could be OpenAI, Azure OpenAI, etc, and for the purposes of this POC I chose to utilise OpenAI and more specifically the GPT-3.5 Turbo model.
What is an LLM
A Large Language Model (LLM) is a type of artificial intelligence model designed to understand and generate human-like language on a large scale. These models are typically based on deep learning architectures, specifically transformer architectures, and are trained on massive datasets containing a diverse range of textual information.
Key characteristics of Large Language Models include:
-
Scale of Data:
- LLMs are trained on vast amounts of text data from diverse sources such as books, articles, websites, and more. This extensive training data helps the model learn the nuances of language and develop a broad understanding of various topics.
-
Transformer Architecture:
- Most LLMs are built on transformer architectures. Transformers are neural network architectures that have proven highly effective for processing sequential data, making them well-suited for natural language processing tasks.
-
Pre-training and Fine-tuning:
- LLMs typically undergo a two-step training process. First, they are pre-trained on a large corpus of text data in an unsupervised manner, learning the statistical patterns and structures of language. After pre-training, the models can be fine-tuned on specific tasks with smaller, task-specific datasets.
-
Versatility in Language Tasks:
- Large Language Models exhibit versatility in performing various language-related tasks, including text generation, completion, summarization, translation, sentiment analysis, question answering, and more. This versatility is a result of the broad and deep knowledge acquired during pre-training.
-
Contextual Understanding:
- LLMs excel in understanding the context in which words and phrases are used. They can generate contextually relevant responses by considering the entire context of a given input sequence, allowing them to produce more coherent and meaningful outputs.
-
GPT-3 Example:
- One prominent example of a Large Language Model is GPT-3 (Generative Pre-trained Transformer 3), developed by OpenAI. GPT-3 is known for its impressive language capabilities, with 175 billion parameters, making it one of the largest language models created.
Below is a snippet of code that performs the following:
- The NuGet package called "Betalgo.OpenAI.GPT3" has been utilised in this POC, this package is deprecated in favour of "Betalgo.OpenAI" however for the purposes of a POC I was happy to utilise this package. Using this package we create an instance of an OpenAPI service client, passing in the OpenAI key taken from the OpenAI account settings.
- The search results returned from the semantic search are processed and saved as rows in a CSV file
- The contents of the CSV file are read, tokenized and returned as a DataFrame.
- OpenAI embeddings are then created from the passed in DataFrame and these are then saved to a separate CSV file.
- Finally the Completion API is called (this API is deprecated and the Chat Completion API should now be used, but for the purposes of the POC I was fine with this) which utilises the initial search query, a prompt and the created embeddings to come up with an answer that relates to the user's initial intent.
// Create OpenAI client (key should be put in config, but fine for POC)
var openAiService = new OpenAIService(new OpenAiOptions()
{
ApiKey = "<openai-key>"
});
// Process the search results, then tokenize the results and finally created embeddings which are saved to a file
SearchResultsProcessor.ProcessSearchResults(semanticSearchResults.Data);
var dataFrame = TextTokenizer.TokenizeTextFile();
await TextEmbedding.CreateEmbeddings(openAiService, dataFrame, "blahblah.com", 100, 150_000);
// Perform chat completion
var answer = await TextAnswers.AnswerQuestion(openAiService, "blahblah.com", request.Query);Embeddings
Embeddings refer to the numerical representations of words, phrases, or sentences that are learned during the training of the model. These embeddings encode semantic information about the language and enable the model to understand the relationships between different words and the context in which they appear.
Here's a breakdown of how embeddings work in the context of large language models:
-
Word Embeddings:
- For individual words, embeddings are vectors in a high-dimensional space. Each word is mapped to a unique vector, and the position of the vector captures information about the word's meaning. Word embeddings are learned during the pretraining phase of the language model.
-
Contextual Embeddings:
- In large language models like GPT (Generative Pre-trained Transformer), the embeddings are contextual, meaning they take into account the surrounding words in a sentence. The model captures not only the meaning of a word but also how its meaning changes based on the context it appears in. This helps the model generate more contextually relevant responses.
-
Training Process:
- During the training process, the language model is exposed to a vast amount of text data. It learns to predict the next word in a sequence or fill in missing words based on the context. This process allows the model to develop embeddings that capture the statistical patterns and semantic relationships present in the training data.
-
Vector Space Representation:
- The embeddings result in a vector space where words with similar meanings are closer together in the space. This vector space representation enables the model to perform tasks like language understanding, completion, and generation by manipulating these vectors.
-
Transfer Learning:
- Large language models are often pretrained on a general language understanding task. Once pretrained, they can be fine-tuned for specific tasks with smaller datasets. The embeddings learned during pretraining serve as a foundation of linguistic knowledge that the model can leverage for various downstream applications.
The following code snippet shows how the embeddings are created and then saved to a separate CSV file.
public static async Task CreateEmbeddings(IOpenAIService openAiService, DataFrame df, string domain, int rpm, int tpm)
{
RateLimiter rpmLimiter = new SlidingWindowRateLimiter(
new SlidingWindowRateLimiterOptions()
{
Window = TimeSpan.FromMinutes(1),
SegmentsPerWindow = 6,
PermitLimit = rpm,
QueueLimit = 1,
QueueProcessingOrder = QueueProcessingOrder.OldestFirst,
AutoReplenishment = true
}
);
RateLimiter tpmLimiter = new TokenBucketRateLimiter(
new TokenBucketRateLimiterOptions()
{
ReplenishmentPeriod = TimeSpan.FromMinutes(1),
TokensPerPeriod = tpm,
TokenLimit = tpm,
QueueLimit = 1,
QueueProcessingOrder = QueueProcessingOrder.OldestFirst,
AutoReplenishment = true
}
);
var embeddings = new List<List<double>>();
for (long rowIndex = 0; rowIndex < df.Rows.Count; rowIndex++)
{
var row = df.Rows[rowIndex];
var text = row[df.Columns.IndexOf("text")].ToString();
var nTokens = int.Parse(row[df.Columns.IndexOf("n_tokens")].ToString() ?? string.Empty);
var leases = await Task.WhenAll(rpmLimiter.AcquireAsync(1).AsTask(), tpmLimiter.AcquireAsync(nTokens).AsTask());
if (!leases.All(l => l.IsAcquired))
{
Console.WriteLine("Failed to acquire the permits.");
return;
}
foreach (RateLimitLease lease in leases)
{
lease.Dispose();
}
var response = await openAiService.Embeddings.CreateEmbedding(new OpenAI.GPT3.ObjectModels.RequestModels.EmbeddingCreateRequest()
{
Input = text,
Model = "text-embedding-ada-002"
});
if ((response?.Data != null) && (response.Successful))
{
embeddings.Add(response.Data[0].Embedding);
}
else
{
Console.WriteLine(response?.Error?.Message);
return;
}
}
// Add the token counts to the DataFrame
var embeddingsColumn = new StringDataFrameColumn("embeddings", embeddings.Select(e => $"[{string.Join(",", e)}]"));
df.Columns.Add(embeddingsColumn);
DataFrame.SaveCsv(df, $"processed/{domain}/embeddings.csv");
}Chat Completion
The final part of the process is to perform the completion of the question that was asked and the snippet of code below shows how this can be achieved.
- First we create a context, this is an important part of the completion process as it reads in the initial embeddings, and also creates a new embedding based on the original search query, from this the calculations are performed for each embedding which at a high-level detail how close the embedding is to the original question embedding, these are all returned as an IEnumerable list of doubles.
- A prompt is created which basically tells the LLM what to do. In the case of this POC the following prompt is created:
Answer the question based on the context below and provide reference links, and if the question can't be answered based on the context, say \"I don't know\"\n\nContext: {context}\n\n---\n\nQuestion: {question}\nAnswer
As you can see the context created in step 1 is added to the prompt along with the original question. - The OpenAI completion API endpoint is then called which returns a completion response and from this we retrieve the answer.
public static async Task<string> AnswerQuestion(
IOpenAIService openAiService,
string domain,
string? question,
string model = "text-davinci-003",
int maxLen = 1800,
string size = "ada",
bool debug = false,
int maxTokens = 150,
string? stopSequence = null)
{
if (question == null)
{
return string.Empty;
}
string context = await CreateContext(openAiService, question, GetEmbeddings(domain), maxLen, size);
if (debug)
{
Console.WriteLine("Context:\n" + context);
Console.WriteLine("\n\n");
}
try
{
var prompt = $"Answer the question based on the context below and provide reference links, and if the question can't be answered based on the context, say \"I don't know\"\n\nContext: {context}\n\n---\n\nQuestion: {question}\nAnswer:";
var completionRequest = new CompletionCreateRequest()
{
Prompt = prompt,
Temperature = 0,
MaxTokens = maxTokens,
TopP = 1,
FrequencyPenalty = 0,
PresencePenalty = 0,
StopAsList = stopSequence != null ? new[] { stopSequence } : null,
Model = model
};
var completionResponse = await openAiService.Completions.CreateCompletion(completionRequest);
return completionResponse.Choices[0].Text.Trim();
}
catch (Exception e)
{
Console.WriteLine(e);
return string.Empty;
}
}
private static async Task<string> CreateContext(IOpenAIService openAiService, string question, DataFrame df, int maxLen = 1800, string size = "ada")
{
List<List<double>> embeddings = df.Rows.Select(row => row[df.Columns.IndexOf("embeddings")].ToString().Trim('[', ']').Split(",").Select(double.Parse).ToList()).ToList();
var response = await openAiService.Embeddings.CreateEmbedding(new EmbeddingCreateRequest()
{
Input = question,
Model = "text-embedding-ada-002"
});
if (!response.Successful)
{
return string.Empty;
}
var qEmbeddings = response.Data[0].Embedding;
IEnumerable<double> distances = DistancesFromEmbeddings(qEmbeddings, embeddings);
var distancesColumn = new PrimitiveDataFrameColumn<double>("distances", distances);
df.Columns.Add(distancesColumn);
DataFrame sortedDf = df.OrderBy("distances");
List<string?> returns = new();
int curLen = 0;
foreach (DataFrameRow row in sortedDf.Rows)
{
curLen += int.Parse(row[df.Columns.IndexOf("n_tokens")].ToString() ?? string.Empty) + 4;
if (curLen > maxLen)
{
break;
}
returns.Add(row[df.Columns.IndexOf("text")].ToString());
}
return string.Join("\n\n###\n\n", returns);
}
private static IEnumerable<double> DistancesFromEmbeddings(IEnumerable<double> qEmbeddings, IEnumerable<IEnumerable<double>> embeddings, string distanceMetric = "cosine")
{
Vector<double> questionVector = Vector<double>.Build.DenseOfArray(qEmbeddings.ToArray());
int numEmbeddings = embeddings.Count();
double[] distances = new double[numEmbeddings];
int index = 0;
foreach (var embedding in embeddings)
{
double[] currentEmbedding = embedding.ToArray();
Vector<double> currentVector = Vector<double>.Build.DenseOfArray(currentEmbedding);
if (distanceMetric == "cosine")
{
double cosineDistance = 1 - (questionVector * currentVector) / (questionVector.L2Norm() * currentVector.L2Norm());
distances[index++] = cosineDistance;
}
else
{
throw new ArgumentException("Unsupported distance metric");
}
}
return distances;
}
private static DataFrame GetEmbeddings(string domain)
{
string csvFilePath = $"processed/{domain}/embeddings.csv";
DataFrame df = DataFrame.LoadCsv(csvFilePath);
return df;
}Summary
This is the first time I have really started to look into and explore the capabilities of AI and how it can be used in conjunction with the Optimizely suite of products. The pairing of Graph, Semantic Search and OpenAI means that you can easily create an AI powered conversational chatbot that will give real value to your customers and allow them to ask questions and get returned answers that are inline with what the user's intent was, there is a lot further that this approach can be taken but for the purposes of a POC I feel that the brief was fully realised.
References
https://cookbook.openai.com/
https://learn.microsoft.com/en-us/dotnet/azure/ai/get-started-app-chat-template?tabs=github-codespaces
https://docs.developers.optimizely.com/platform-optimizely/v1.4.0-optimizely-graph/docs/installation-and-configuration
https://docs.developers.optimizely.com/platform-optimizely/v1.4.0-optimizely-graph/docs/event-driven-synchronization
https://docs.developers.optimizely.com/platform-optimizely/v1.4.0-optimizely-graph/docs/scheduled-synchronization
https://docs.developers.optimizely.com/platform-optimizely/v1.4.0-optimizely-graph/docs/semantic-search
https://openai.com/

Comments