
Do you know what I mean? Introducing Semantic Search in Optimizely Graph
It seems not long time ago that search engines allowed users to search beyond strings and match on words. Understanding the basic structure of a natural language was good enough for search engines to move beyond string matching (like done in relational databases) and match on so-called tokens. Often, these tokens are words. A word is a basic element of a language that has meaning. However, search engines were not intelligent enough to understand the meaning of these words. Instead of matching on a very long string, it would be matching on tokens. Basically, all tokens were treated as a bag of words, where we did not assume any relation between these words. A naïve, but very effective approach in information retrieval (IR, or the science behind search).
But with the advent of deep learning and other AI advancements, we are seeing new developments in search engines as well in the area of semantic search. In this post, I will try to explain the history behind the technology, the origin of the most important terminology used in this domain, and what this technology is. And how we support this in Optimizely Graph, or Graph in short.
How a full-text search engine works in a nutshell
Full-text search engines store text and return results efficiently. Key features are advanced matching on these texts, blazing retrieval speed, and intelligent scoring of results, so that users get most relevant information as fast as possible.
Data is stored by creating tokens. Tokens created for indexing are commonly stored in full-text search engines with a special data structure called the inverted index. Basically, it is a special table optimized for quick lookups. The index is called inverted, because the tokens (and not the documents) are stored in a column store with extra dimensions, like the reference to the documents containing the token, its frequency in a document, the positions of a token in a stream of tokens, etc. Here we see a low-level visualization of this in Lucene, which is an open-source core search library that drives a lot of the site search on the web. We see that content and its metadata is indexed into special files, and together these are called a index segment. An index consists of these segments.
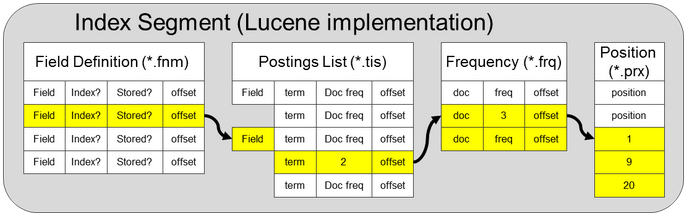
Crucially here, is that these dimensions are used to represent a token in a vector space. We speak then of term-based vectors, or sparse embeddings, because there can be one (token present or not present) or many dimensions, and since most documents contain only a small subset of the full vocabulary, these vectors are considered sparse since zero values will be plentiful. Note that uninverted stores (so called doc values) are also used as explained in this blog post, for example to efficiently create facets and drive analytics.
Anyway, the sparse vector embeddings are used to match and most importantly, rank the results. In 1975, G. Salton et al. came up with the vector space model for indexing. This was purely an algebraic approach, but this was extended with a probabilistic relevance model in the 1970s and 1980s by Stephen E. Robertson, Karen Spärck Jones, and others and eventually presented it in 1994 at TREC (a conference where information retrieval researchers work on text retrieval methodologies) as Okapi BM25, or BM25 in short.
The basic idea of BM25 is that the search engine considers the frequency of a word, the number of documents containing a word (with the idea to make more frequent terms ranked lower), document length normalization, and query term saturation to mitigate the impact of very frequent words. It is used till now as the baseline of relevance ranking for full-text search and the default ranking used in solutions like Elasticsearch and Apache Solr. And not surprisingly, Optimizely Graph uses BM25 also as the default relevance ranking model. Search & Navigation though, is still using the vector space model from G. Salton et al.
That is not to say that BM25 is the best model out there. A plethora of research papers have shown that using a pure probabilistic model with language models can outperform BM25. And ranking results is much more sophisticated than just statistics and probability theory on the tokens that you have stored. Search has been significantly improved by incorporating many other signals in ranking models. Can anyone still remember PageRank? Google made web search commodity because of the highly successful application of this, where the number of incoming links to a page could be used to boost, so frequently linked pages showed up higher. Google has said that more than 200 signals are used for their search. Indeed, using signals like these are part of artificial intelligence, which helps to improve getting the most relevant content shown on the screen of the user.
AI comes knocking at the door
We thought that web search was a solved problem for most users. Users seem satisfied with what they got from Google. However, with the boom happening with generative AI, made possible with the huge improvements in deep learning, new ways to interact with information and new insights that we can gain have been unlocked. Instead of scrolling through a list of text, chat bots can directly deliver the answer that you were looking for. Talking to a device and get a satisfying verbal response from that device is no longer science-fiction.
Key to generative AI technology is the concept of transforming text into numbers. We need this, because machine learning models understand numbers, but not words. We can train on a lot of text and build so called Large Language Models (LLMs), which consists of numerical representations. To understand this core technology, I can recommend the visual explanation on transformers here. A word can be associated with multiple dimensions based on linguistic features, which are represented as vectors, and combined they are called an embedding. They are coordinates in the vector space. The number of dimensions will be limited because only useful ones are selected and used. That is why we call these numbers also dense vector embeddings. This is different compared to the sparse vector embeddings we calculate from the tokens stored in an inverted index.
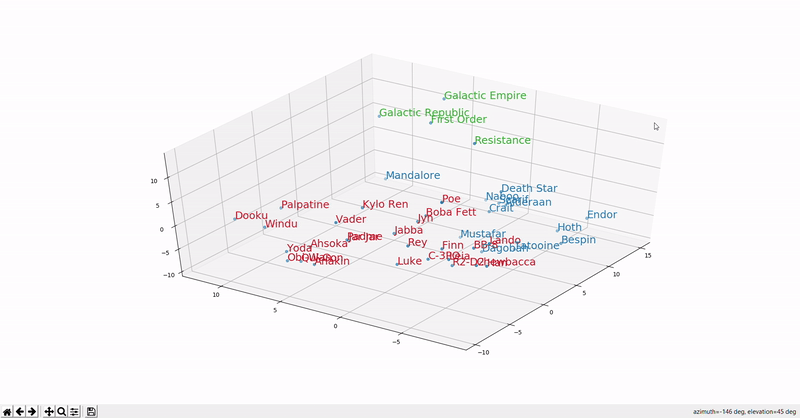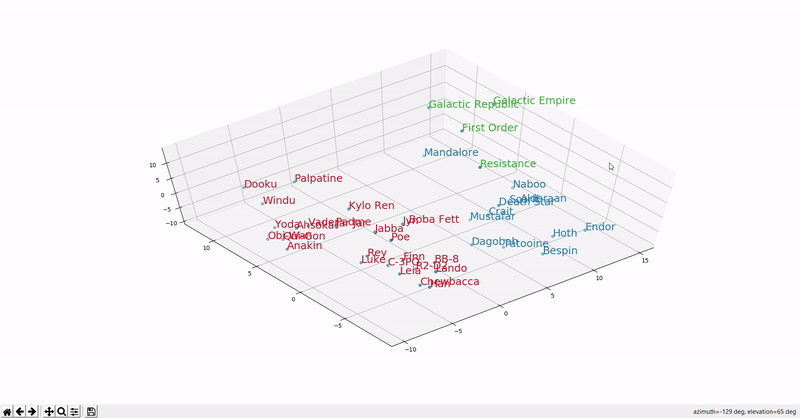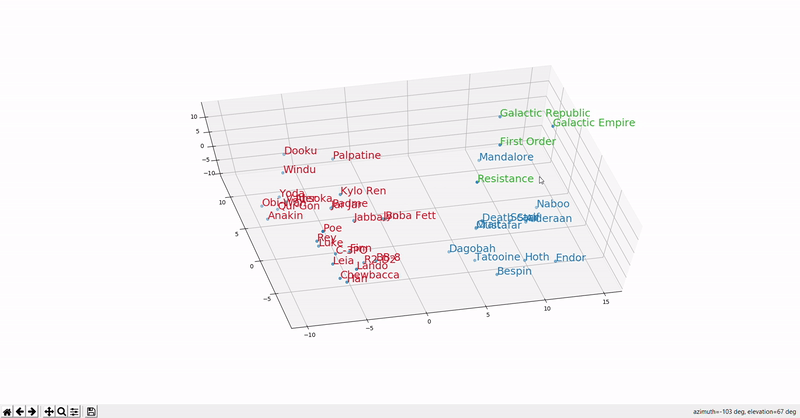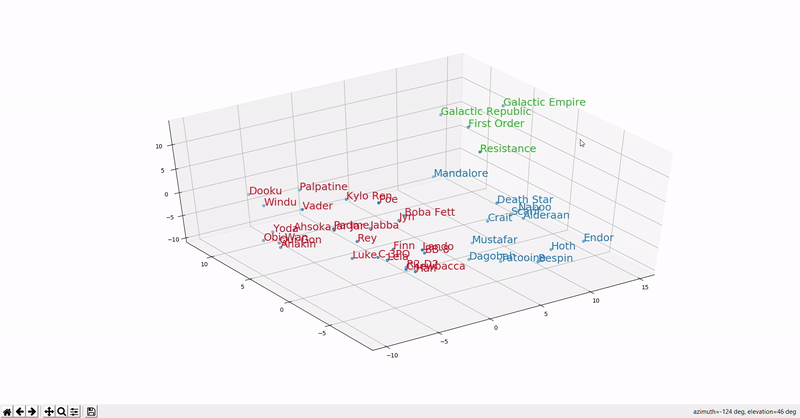
This example shows how we can visualize embeddings computed from Star Wars in the vector space (courtesy @Marcus Alder). So, for example, based on the same dimensions, we will see that words that have similar dimensions will be located closer to each other in the vector space. A word like “cola” will be in a shorter distance to “cold beverage” than “hot chocolate milk”. Or in this visualization, "Anakin" will be closer to "Luke" than "Endor".
Why we need semantic search
The idea of semantic search is not new, but it has become a new paradigm in industry. It is also called (though not necessarily synonyms) neural search, vector search, dense neural retrieval, etc. The idea is that the intent of searchers is understood by the search engine by understanding the meaning of the words that it gets as input. It is made possible now with LLMs, which give us the embeddings. And not to forget, crucially, we have vector search support in search engines to do vector similarity search using similarities like Euclidian, dot-product or Cosine. Vector search is here K-nearest neighbor search on the embeddings. With approximate nearest neighbor search using Hierarchical Navigable Small World (HNSW) graphs, we can do this at scale and efficiently with good performance.
The limitation of standard full-text search with keyword matching is well known as the vocabulary mismatch problem. Relevant content may not be found by site visitors when they use the all-important search box (=3x more likely to convert), because the words that they use in their queries may not occur in the content that you have created. In the worst case, the dreadful “no results found” is shown, resulting in a missed chance to convert and perhaps even churn. Synonyms can be used to solve this problem. However, creating synonym lists is time-consuming and require considerable labor though. And likely, you will always play catch-up. Moreover, with semantic search you can formulate your queries in natural language, enabling better ways to deal with queries.
Solving the problem of the vocabulary mismatch is one of the quick wins. Improving the relevance ranking is another. We can boost relevant content to the top by combining scores from semantic search with standard BM25 relevance ranking. It is crucial that we do not only return results, but also return them in the best relevant order. The result that you see first has a greater chance to be clicked on. Experiments (see for example here, here and here) have shown that combining both keyword-based (lexical) ranking with BM25 and vector-based search, an approach called hybrid search, works better than doing only keyword search or vector-search. And using pure vector search is not always beating BM25, especially in special verticals.
Another common application of semantic search is reducing very convincing looking, but false information returned by chatbots driven by LLMs. A phenomenon known as hallucination. A very popular approach now is using Retrieval Augmented Generation (RAG). The quality of LLMs is improved by using RAG. It offers transparency to the LLMs so the answers can be checked by its sources. Models have access to the most current, reliable facts, and users have access to the model’s sources, ensuring that its claims can be checked for accuracy and ultimately trusted. Imagine adding a chatbot powered by your content on your site using Optimizely Graph in a not too distant future. Wouldn't that be awesome?
Semantic search in Optimizely Graph
Our implementation of semantic search with Graph has been released. We offer it as-a-service and have done the heavy-lifting for you. The feature is experimental now, which means that the results you get now may change in the future, likely for the better as we will try to improve on it. You can find the documentation on Optimizely Graph's semantic search here. We use a pre-trained model that has been trained on a plethora of well-known websites such as Wikipedia and Reddit, using over 1 billion sentences. The model has been trained on English, and works on English content.
You can start by synchronizing your content, but please define fields that you think will be useful for full-text search by setting the property as “searchable”. We support semantic search for full-text search with the field _fulltext and other searchable fields using the contains and match operators in our query language. You can enable semantic search by adding the SEMANTIC ranking enum in the orderBy argument. That’s it!
{
Content(orderBy: { _ranking: SEMANTIC }, where: { _fulltext: { contains: "action movie" } }) {
total
items {
Name
_fulltext
}
}
}And it should return results that are about an action movie, even when action movie is not mentioned in your content. For example:
{
"Content": {
"total": 4,
"items": [
{
"Name": "Standard Page 12",
"MainBody": "Wild Wild West is a 1999 American steampunk Western film co-produced and directed by Barry Sonnenfeld and written by S. S. Wilson and Brent Maddock alongside Jeffrey Price and Peter S. Seaman, from a story penned by brothers Jim and John Thomas. Loosely adapted from The Wild Wild West, a 1960s television series created by Michael Garrison, it is the only production since the television film More Wild Wild West (1980) to feature the characters from the original series. The film stars Will Smith (who previously collaborated with Sonnenfeld on Men in Black two years earlier in 1997) and Kevin Kline as two U.S. Secret Service agents who work together to protect U.S. President Ulysses S. Grant (Kline, in a dual role) and the United States from all manner of dangerous threats during the American Old West.",
"_fulltext": [
"Wild Wild West is a 1999 American steampunk Western film co-produced and directed by Barry Sonnenfeld and written by S. S. Wilson and Brent Maddock alongside Jeffrey Price and Peter S. Seaman, from a story penned by brothers Jim and John Thomas. Loosely adapted from The Wild Wild West, a 1960s television series created by Michael Garrison, it is the only production since the television film More Wild Wild West (1980) to feature the characters from the original series. The film stars Will Smith (who previously collaborated with Sonnenfeld on Men in Black two years earlier in 1997) and Kevin Kline as two U.S. Secret Service agents who work together to protect U.S. President Ulysses S. Grant (Kline, in a dual role) and the United States from all manner of dangerous threats during the American Old West.",
"Standard Page 12"
]
},
{
"Name": "Temporary Page Title",
"MainBody": "The American frontier, also known as the Old West, popularly known as the Wild West, encompasses the geography, history, folklore, and culture associated with the forward wave of American expansion in mainland North America that began with European colonial settlements in the early 17th century and ended with the admission of the last few contiguous western territories as states in 1912. This era of massive migration and settlement was particularly encouraged by President Thomas Jefferson following the Louisiana Purchase, giving rise to the expansionist attitude known as \"Manifest Destiny\" and the historians' \"Frontier Thesis\". The legends, historical events and folklore of the American frontier have embedded themselves into United States culture so much so that the Old West, and the Western genre of media specifically, has become one of the defining periods of American national identity.",
"_fulltext": [
"The American frontier, also known as the Old West, popularly known as the Wild West, encompasses the geography, history, folklore, and culture associated with the forward wave of American expansion in mainland North America that began with European colonial settlements in the early 17th century and ended with the admission of the last few contiguous western territories as states in 1912. This era of massive migration and settlement was particularly encouraged by President Thomas Jefferson following the Louisiana Purchase, giving rise to the expansionist attitude known as \"Manifest Destiny\" and the historians' \"Frontier Thesis\". The legends, historical events and folklore of the American frontier have embedded themselves into United States culture so much so that the Old West, and the Western genre of media specifically, has become one of the defining periods of American national identity.",
"Temporary Page Title"
]
},
{
"Name": "Wilder Westen",
"MainBody": "Wilder Westen ist eine – geographisch und historisch grob eingegrenzte – umgangssprachliche Bezeichnung für die ungefähr westlich des Mississippi gelegenen Gebiete der heutigen Vereinigten Staaten. In der auch als „Pionierzeit“ bezeichneten Ära des 19. Jahrhunderts waren sie noch nicht als Bundesstaaten in die Union der Vereinigten Staaten aufgenommen. Im Verlauf der voranschreitenden Landnahme und Urbanisierung nahm die Besiedlung dieser Regionen vor allem durch Angloamerikaner – bzw. aus Europa stammende Immigranten – kontinuierlich zu, bis die Gebiete um 1890 in den organisierten Territorien der Vereinigten Staaten aufgingen. Symbolisch stehen die Öffnung der letzten Indianerterritorien im späteren US-Bundesstaat Oklahoma für die Besiedlung durch Kolonisten 1889–1895 durch eine Serie von Land Runs und das Massaker der United States Army an etwa 200 bis 300 Lakota am Wounded Knee Creek/South Dakota im Dezember 1890 für das Ende der Zeit des Wilden Westens. Mit diesen Ereignissen galten die Indianerkriege ebenso als abgeschlossen wie die Kolonisation der bis dahin von den Vereinigten Staaten beanspruchten Hoheitsgebiete (engl. territories) durch die aus Europa eingewanderten Siedler.",
"_fulltext": [
"Wilder Westen ist eine – geographisch und historisch grob eingegrenzte – umgangssprachliche Bezeichnung für die ungefähr westlich des Mississippi gelegenen Gebiete der heutigen Vereinigten Staaten. In der auch als „Pionierzeit“ bezeichneten Ära des 19. Jahrhunderts waren sie noch nicht als Bundesstaaten in die Union der Vereinigten Staaten aufgenommen. Im Verlauf der voranschreitenden Landnahme und Urbanisierung nahm die Besiedlung dieser Regionen vor allem durch Angloamerikaner – bzw. aus Europa stammende Immigranten – kontinuierlich zu, bis die Gebiete um 1890 in den organisierten Territorien der Vereinigten Staaten aufgingen. Symbolisch stehen die Öffnung der letzten Indianerterritorien im späteren US-Bundesstaat Oklahoma für die Besiedlung durch Kolonisten 1889–1895 durch eine Serie von Land Runs und das Massaker der United States Army an etwa 200 bis 300 Lakota am Wounded Knee Creek/South Dakota im Dezember 1890 für das Ende der Zeit des Wilden Westens. Mit diesen Ereignissen galten die Indianerkriege ebenso als abgeschlossen wie die Kolonisation der bis dahin von den Vereinigten Staaten beanspruchten Hoheitsgebiete (engl. territories) durch die aus Europa eingewanderten Siedler.",
"Wilder Westen"
]
},
{
"Name": "Arnold Schwarzenegger",
"MainBody": null,
"_fulltext": [
"Arnold Schwarzenegger"
]
}
]
}
}Curious about how well it works on your content? Give Optimizely Graph a try.
Wrap up
I have presented the technical background of semantic search, explained some key concepts and terminology. The different applications of semantic search. And how you can use it in Graph. With the introduction of semantic search, we have taken a big step in the mission to support you with AI search as previously posited in my blog post "Why Optimizely Graph is Search as a Service". So what are the next steps with AI-driven search? There are a few things. Currently, the model that we use supports English. We will soon release support for other languages, including the frequently requested Nordic languages. Another thing is improving the ranking together with standard relevance scoring. We are also looking into supporting custom models too, DIY solutions using for example LangChain, and use Graph to ground the truth in chatbots.
What are the next steps besides improving on AI? Graph gets powerful as it becomes the gateway to your content. Having good search will prove to be crucial here to achieve continuous success. Creating great search experiences is an art. The importance of search analytics and tracking with both online and offline experimentation will become clear as new features that show how science can meet art, how we can measure performance and experiment. This also allows us to support personalization with Graph. In a future blog post, I will bring you an update on that. Have other ideas? Feel free to share or upvote on existing ideas.
Optimizely Graph allows you to aggregate on your content and other data with GraphQL, including using advanced search functionality driven by AI, so you can deliver it to any channel, app or device. It is part of the Optimizely PaaS offering as well as Optimizely One.
Comments