
Performance checklist
One of my favorite areas in software development is getting a solution to run really fast. This is pretty easy for small websites but gets exponentially tricky for larger websites under heavy load. I've worked with improving performance on Optimizely CMS and similar .NET sites for close to 20 years now and below are my top suggestions for frontend, backend, CMS specific and team work processes. But let's start by asking an important question:
Why is performance vital to a site?
Conversion
Performance might seem technical and boring but it is essential to understand the underlying business case here. You, as a developer, will not get time to focus on performance if you can't explain why.
Without decent performance a large percent of the total revenue from the site will be lost. It is even possible to estimate how much and for major sites we are talking millions $USD.
Though content and nice design is good, if the page doesn't respond fast enough, your customer will get bored and never see it. Let's check out some statistics:
Amazon found out that 0.1s extra load time cost them 1% in sales.
Google reports that increasing page load time from
1s to 5s - the probability of bounce increases 90%
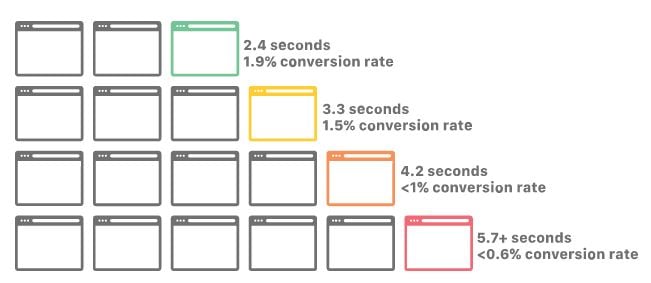
Using these numbers for a site that has an annual revenue of 100M $USD and a response time of 4.2s, the Amazon estimate will be 2/0.1* 1% = 20% increased revenue = +20M $USD annual revenue.
Performance of the website is a business critical problem whether the information on the website is generating revenue or saving lives.
Protection vs denial of service attacks (DDoS)
Good performance combined with a nice CDN like Cloudflare also protects against DDoS attacks. The better performance your site has overall, the more effort it takes to bring it down with bots. For best effect strive for fast response times, good firewall that can filter out bots and elastic scaling that can increase computation power when needed. Worth noting that Optimizely DXP solves both elastic scaling and CDN with DDoS protection and this checklist will solve the response times.
Added some levels to indicate in what order I would do them in.
- Level A - Most important fixes / low effort that all sites should have yesterday.
- Level AA - Important / medium effort
- Level AAA - If you complete these you are probably top 1% of the sites out there
How can performance be improved?
Measure performance (A)
Always start by measuring and proving what is wrong. Avoid randomly improving code in your application. For this a good tool to measure performance effectively is needed. My personal tool of choice here is application insights from Microsoft to check server statistic but there are many others that will work. Visual Studio has a decent tool for checking CPU cost of methods. dotTrace from jetbrains will also work. I prefer to work with application insights because I can keep that up and running on production environment and it's also the standard tool used by DXP.
For client rendering statistics, google chrome developer tools works well enough. Lighthouse report usually gives a good hint on any issues.
- The request total response time from server
- The request rendering time on client
(These two together will tell you if you have a frontend issue or a backend issue) - The number of outgoing calls a page has normally (SQL and web api calls) and how long these take
(Aim for 0-2 outgoing calls per page request on average. If you have many more, the application is likelly to be vulnerable when load increases)
This will tell you if you have a n+1 issue with some product list or similar where you do a separate expensive call for each item in the list. This should be avoided.
Measure performance (client+server) before and after each deploy to production and use it as an KPI that is tracked by product owner and stakeholders.
Checklist of performance problems and solutions
Frontend technical checklist
- Use heavy javascript frameworks with care (A)
Javascript frameworks like react and vue are fun to use but if something can be decently built using html and css only, do it. If you really need heavy js frameworks for part of your application, then use them on separate pages only to maximize performance for the rest of the application.This is also why my recommendation is also to stay away from headless for normal content heavy parts of the sites and only use for user interaction heavy functionality. Below are statistics of average rendering time depending on framework from httparchive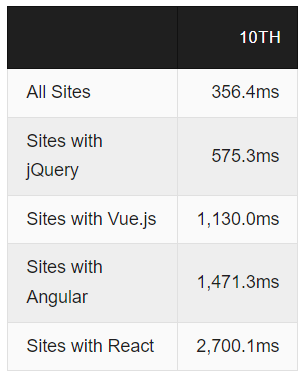
Does React bring enough worth to warrant 2.7s extra load time to your solution? That is 27% lost sales revenue if used on public product pages (according to Amazon study). Do use it, but think really hard on where and when it is needed. It's easy to build a huge monolithic javascript frontend that is hell to optimize / replace. - Minimize number of requests and payload (A)
CSS and javascript should be bundled, gzipped/brotli and minified. Brotli is the best compression and can be enabled by DXP but still as an experimental feature. I'll personally stick to gzip for now. If your main issue is slow frontend and large scripts, give brotli compression a shot. - Set max age and allow public caching (A)
by using response headers on css js. Will also activate CDN for these resources and help keeping server CPU fast. - Set a versioning number or hash on css, js and image filenames (AA)
to simplify updates combined with caching. There is a nuget package to create a unique hash path for images for CMS called Episerver.CDNSupport that simplifies this for image blobs. - Use a CDN to serve images (AA)
Cloudflare is used for CMS cloud. Check that you send the correct cache headers from server and get a HIT in response headers for images from cloudfront. - Can some things be loaded after the page has rendered (AA)
Can some functionality be hidden by default and rendered only when needed to maximize rendering performance above the fold? - Avoid making the page too heavy - scale images (A)
For mobile users especially, the total size in Mb of page is vital to keep to a minimum. Do you really need that heavy image slider functionality at page load if it means increasing your bounce rate on a performance critical page? Scale those images by using image processor (v11) , or this for CMS 12 or similar addon to generate mobile friendly image sizes. Don't trust editors to remember to do it. - Can some html be loaded async? (AA)
I'm looking at you "mobile menu". Often sites have a large part of their site tree with 1000s of html tags here. - Avoid changing layout as things are loaded (AAA)
Try to have correct height and width by setting lineheights, image sizes etc correct from start. - Make the initial view of page (above the fold) super fast by using inline scripts and css for this part (AAA)
The rest of supportive functionality can be done the normal way with external css and js files. Try to avoid blocking rendering by using defer on js that is not needed for initial view.
Optimizely CMS specific checklist
- Avoid having more than a hundred content items below a single node (A)
Insert a separate container page and divide the content items by date or alphabetically. If you don't, edit mode will not work well and performance for GetChildren method will be problematic for that node. - Avoid loading 100s of content items for a single page request (A)
Often this is done when constructing the menu, especially the mobile one. Avoid loading the entire tree structure at once and load them only when user expand that part of tree. Be on a lookout for GetChildren that is called recursEvily over a large part of the content tree or GetDescendants followed by loading the actual pages sequentially. If any of these returns 100s of pages, try to solve it in another way. Sure, these calls get cached eventually by the CMS which will save you from crashing the site most of the time but for larger sites with hundreds of editors this is not something you want to rely on. Cache end result with object cache, rethink the design slightly or use Episerver Find are your main tools to avoid this. - Personalization, access rights and caching (AA)
I usually stay away from output cache and using CDN for html (default setting is not to cache html for DXP for this reason) and instead try to use object caching for expensive calls to avoid issues with this. But if you need to also use CDN or output caching to get that extra boost of performance, you will need to remember personalization / visitor groups. If you cache and minimize external calls for pages and cache the menu separately for anonoumous users you can normally solve it without the need of CDN and output cache.
If you decide to go with output cache anyway, there is a big advantage if the html sent with the initial response is free from personalization. Then personalized funtionality can be rendered later using the content delivery api + javascript. Then output cache and CDN can be applied to the server rendered html if needed. - Avoid looking up content in structure with GetChildren (A)
Use a content reference on start page if possible. Use Episerver Find if needed. Crawling through the page tree with GetChildren gets expensive. - Try to avoid using nested blocks (AAA)
Blocks are great but try to avoid unneccessary complexity. Do your editors really need that degree of freedom at the expense of complexity?
It can normally be solved in a simpler way. Will impact editor experience more than performance though so ranking this low in this checklist. - Custom visitor group criteria (AA)
If you build new criterias, ensure these don't create a lookup per request for each user. One request to database is ok per user. One for every request is usually not. Since these are evaluated per request you need to be extra careful with these so that they are fast. - For simple blocks that don't need a controller, don't use one (AAA)
If you are simply passing along the CMS content and rendering it, you don't need a controller. If you need to load additional data via an api and do more complex work, do use a controller. - Check log level (A)
Avoid setting log to info or all in production except during troubleshooting. Log4net set to info on root will bring down your production site. - Search & Navigation for menues (formerly Episerver Find) (AA)
If ýou are using Find to build menues, find news articles to display in a list or something similar per page request, caching the result is needed. Find has a nice extension for that. Only cache things shown to anon users to avoid issues with access rights and personalization. If you don't do this, there is a risk of both poor performance and running into request limitations for Find.
var result = client.Search<BlogPost>() .StaticallyCacheFor(TimeSpan.FromMinutes(5)) .GetResult();Check through application insights and check how many requests are done towards Find to see if you have an issue with this. Normal site search is normally not neccessary to cache.
- Elastic scaling of servers (AAA)
DXP uses Azure webapps below the hood that automatically can be increased if CPU runs into issues during high load. This is an amazing technology that is needed for large scale sites. If you don't use DXP, it can be set up using Azure manually as well. If you have a well trained cloud savvy organisation already and have very special demands on infrastructure in cloud, that is definitely an option. I would recommend DXP as the main option though. On premise is possible but then you will lose the elastic scaling ability which increases likelyhood of CPU related performance issues. - Warmup sites (AAA)
Many sites need to run a few requests to populate cache etc before starting to respond well. This is useful both when the site is elastically scaling and when deploying new code to the site to avoid performance drops. The start page is automatically warmed up by default in DXP. If you need other pages to be hit with a request that is possible as well.
Read more in detail using this article:
https://world.optimizely.com/documentation/developer-guides/archive/dxp-cloud-services/development-considerations/warm-up-of-sites/
Backend general checklist
- Avoid multiple dependecy calls for a page (A)
If you get data from an api, cache it if possible. If you are getting lists of items, make sure you are getting enough information to avoid having to call the api again for each item. Use a scheduled job if possible to load expensive information in advance, store in Episerver Find / DDS or as content items in content tree since these are cached. DDS is pretty slow so only a good idea for very small amounts of data like settings. In application insights you can check how many requests are made out from your application to be able to render a page. Keep those few and fast. One quick external call on average is ok. More than that per request you are normally in trouble. If you have as many as 10 or more per page request it will very difficult to keep fast and stable. This is probably the number one reason sites go down in my experience. Good to measure after each deploy for key pages. - Don't scale images for every request (A)
Make sure they are cached in CDN after or cache the scaled images in some other way - Avoid using locks (A)
Locks in code to avoid a method running twice at the same time looks easy but can often cause serious deadlocks in production. Try to solve in another way by making your code run well even if it happens to run twice sometimes (idempotent). If you really need to use locks, make sure to log extensively to be able to find problems quick. Symptoms for a problem with lock is low CPU but high request times from server while dependencies response fast. Use memory dumps from production to prove the problem. These performance problems are the most difficult to find. I've seen a lock that wasn't needed bring down quite a few large sites. - Use load balancing (AA)
Make sure they have the same machinekey and avoid storing objects in session state. CMS does this by default in DXP if you use that. Avoid using session state in your solution to simplify sharing load. If you cache expensive calls the standard cache to use is the syncronized object cache that automatically invalidates cache on all servers when it expires. - Use IHttpClientFactory (AA)
HttpClient is the class that is used to connect to external apis. Unfortunately it is really difficult to use correctly. Always instantiate using the IHttpClientFactory. .NET 5 has good support for this by passing in the HttpClient in constructor if you are using CMS 12. Below that you will need a separate package from Microsoft.Extensions to make it work but it's also possible for CMS 11 and .NET 4.7. If you see socketexceptions during heavy load in the logs, that is a good indication that you need to check this. Also made my integration calls around 30% faster just by fixing this. - Use small cookies (AA)
Avoid storing too much data in cookies. Use ids instead of storing entire large objects if needed. I've seen a large intranet get really slow from this single issue. Difficult to find. I remember I got slow response time even for static resources like css and js because of this. - Use scheduled jobs / queue for expensive operations (AA)
Some things like import jobs, sending notification emails etc can run during night time to keep server happy during daytime. For expensive operations that can be done without user feedback, using hangfire or a custom queue in Azure can be a good option. - Use CMS 12 and .NET 5+ if possible (AA)
.NET 5+ has a lot of free performance gains out of the box. Enitiy Framework core 5+ for building custom database implementations can be lightning fast. I'm still amazed of an api we build that has a 5-10ms response time with quite a few tables and millions of rows in database. - Use streams, avoid byte[] (AA)
Avoid passing byte[] along. If you see a byte[] somewhere in code, check if it's possible to implement as a stream. For instance, uploading a profile picture to file doesn't have to upload the entire image into a byte[] first and then store to disk. .NET memory management will not like you if pass along a lot of heavy objects like byte[]. - Avoid microservice architecture if you don't need it (AA)
Microservices can be useful for very large solutions especially if they can be called directly from frontend, the solution have multiple clients that need the data (like external system / phone app) and it has multiple development teams. They do add an additional layer / integration call though and increase the complexity of the solution. Debugging and monitoring will become trickier. For smaller single team solutions without multiple client solutions, they are often a waste of implementation time and performance. That being said, they have helped me upgrading a huge solution one piece at the time which I like. - Shut down integrations that doesn't work (AAA)
Polly is a good framework that acts as a circuitbreaker. You can also use the blocks functionality in CMS to act as a feature switch and shut off the functionality that isn't working manually. Integrations that starts misbehaving can pull down your solution if you don't do this. Monitor integrations using Application Insights. - Async await (AAA)
Can be useful to increase throughput through application. Do mind the additional complexity though. Easy to create deadlocks if not used all the way. If you need to do x calls that are not depending on eachother, start the calls at once and then await them after to get them all to run in parallell. This can save quite some time in some cases. Do use on new sites. Probably not worth the hassle on older that doesn't already have it. Await creates a state machine, creates a new thread and runs the code on that one and then switches back to run on original thread. It also handles exceptions in a nice way. These facts are key to optimize how to use it.
-Set .ConfigureAwait(false) normally to improve performance and avoid deadlocks. This will skip the second thread switch that you normally don't need.
-Avoid return await. Why create a state machine if you are not going to run any code but return right away? Return the task instead and let calling method have the await instead.
Task.Run can definitely run async methods but will not have the good exception handling. Use await instead if possible.
If you need to run an async method syncronous, use .GetAwaiter().GetResult() as last resort instead of .Result or .Wait to get better exception handling. If possible, rewrite to use async await the whole way instead of mixing.
Best practice for async await
Teamwork checklist
Almost all websites work well when they are small and new but then slowly start to degrade over the years. How you teamwork and your development process during this time will affect the performance of the solution in the long run. These actions below are mindset and process improvement to avoid ending up with a huge solution that is slowly dying. As a tech lead for a major solution, keep these in mind
- Cognitive limit (A)
It's only possible to improve architecture on a solution if you can understand it. The size and the complexity of the solution is the enemy here. This is related to all other points in this section. - Non-functional requirements (NFRs) should be part of the requirements (A)
The problem with performance is that the business are usually focused on feature development. Things that are visible and bring instant value to users. Someone needs to be in charge of adding architecture upgrades and performance improvements to the backlog. One way is to set a fixed percentage like 30% of storypoints / development budget to go to improving architecture (tech enablers). Team needs to help product owner here or it tends to not get done. Only focusing on features and adding time / budget pressure on team will result in a very slow site in the long run, 100% of the times. - Methodology - fixed price or agile? (A)
Fixed priced project are more prone to performance problems due to the above. They often lack requirements for NFRs and time pressure limiting team own initiatives will more likely result in problems in this section. For business critical major sites, use an agile approach and don't ignore the NFRs part of the solution. Use the most senior developer to help with user stories for this. - No single part of the solution should be mainained by multiple teams (AA)
This doesn't place a limit of the size of the solution. It just means that if you need both a fast car and the ability to dig, you build two different vehicles instead trying to build a single really fast tractor.
If the solution gets bigger than a single team can autonomously maintain, start thinking on how to split it up in vertical slices into multiple loosely coupled solutions that can be deployed separately. Do this early to avoid SEO issues later on. In DXP you can first start by extracting a part of the solution into a separate site since you can have multiple sites without additional license fees. If that site grows in functionality to the size that it needs a separate team, split it off into a new instance so that it can be upgraded and deployed separately.
Improving performance means architecture changes. Architecture changes when you have several teams and a gigantic solution are painful and tend to not get done. Don't underestimate this business risk. I would rate this as A for importantce but setting it as AA because it can be problematic to shift to for existing monolithic sites. - Make it easy to phase out functionality (AA)
As the site grows in functionality, it will be more difficult to maintain and keep the same performance. For a large site with an expected lifespan more than a decade you need to start planning how to remove functionality from the start. In the long run that will start to hurt maintainability and performance.
-Use Episerver blocks as feature switches for major functionality. If you have implemented a new functionality using a block, it will be easy to gradually test it and phase it in for a subset of your users. Perfect for limiting blast radius if something goes wrong and simplify deploys. They are also easy to phase out when they need to be replaced by a new functionality. Don't overuse them though and try not to nest them since it makes the site unnecessary complex.
-Use feature folders in .NET to simplify removing functionality
-Have a plan to remove functionality from frontend, including corresponding js,html and css. Feature folders and some kind of modularization can usually go a long way towards this goal.
Happy optimizing!
If you have more suggestions on performance improvements or if some of this advice help you, drop a comment!
Great list, Daniel.
I would add:
Thx!
I added a small section about CDN and output cache + personalization. I normally try to avoid using it for those reasons for dynamic html from server. Access rights and personalization becomes much trickier.
Loading large sets of content in any way for each requests will normally get you in trouble sooner or later yes. I added some extra content to that as well. Sure they are "often" cached, but for large sites you also have 100s of editors sitting around killing that cache frequently. And that will hit all your frontend servers at the pretty much the same time so should be avoided with either a separate cache or rethink functionality. I've seen it spike the CPU to 100% on quite a few large sites. It doesn't really show up as a lot of external calls in application insight but more as CPU issue (after it's been cached). I've seen menues that takes between 1-5s to render serverside because of this. Cache them for anonymous users / rebuild to only show first 2 levels and you are down to 0.001s.
Also, I really dislike that long startup time for the site as a developer so don't totally rely on Episervers cache on GetChildren().
Hope you don’t mind but a few thoughts and added suggestions
A few other things for the front end
Backend
Great additions @Scott Reed!
Love this post!
Personally I've been on the fence about always recommending the use of Async on standard Controllers for cloud hosted solutions like DXP but would love your opinions?
While the asynchronous paradigm does optimise the use of the thread pool which is useful especially in traffic spikes, it is often but not always depending on some project specific factors less of an issue in scalable cloud architecture like DXP.
The main disadvantage I've seen are:
Technical Standards
Developers need to very well understand how to code asynchrously. Without strong technical stanadards the final solution can be less performant with increased risks of deadlocks for example.
On a well run project this wont be such an issue.
However I've inherited code bases in the past that obviously started with the use of asynchronous controllers but veered off course across layers and you are left with a bundle of technical debt.
Maintainability
The cost of maintaining the code base can be increased with more considerations than a standard synchronous programming model.
For new projects I'd use async await all the way for all controllers. I do have mixed feelings about async await pattern though as it adds more complexity than you might guess at first look.
For old I'd skip it if it doesn't exist. It's problematic to refactor a large existing codebase to say the least. Normally you have better things to improve in the list above. Some of the items above like caching menu can give a 50 times improvement to load time in some cases and be done in a day or two. Async await pattern gives a slight improvement but can cost weeks to get stable on a large solution.
So async pattern I would say is "nice to have" but not worth refactor an entire solution for.
Thanks for sharing Daniel and a great summary!