
Azure Function App for PDF Creation With Syncfusion .Net PDF Framework
We have a couple of use cases that require internal and external users to print content in PDF format. We've offloaded this functionality from the DXP Web App to an Azure Function App running in a Docker container. We make use of the Syncfusion .Net PDF Framework (note: subscription required). Our first use case allows you to provide a URL to the endpoint for printing. The second use case involves POSTing an array of XHTML content to the endpoint.
Create the Azure Function App
In Visual Studio create a new project and choose Azure Functions.
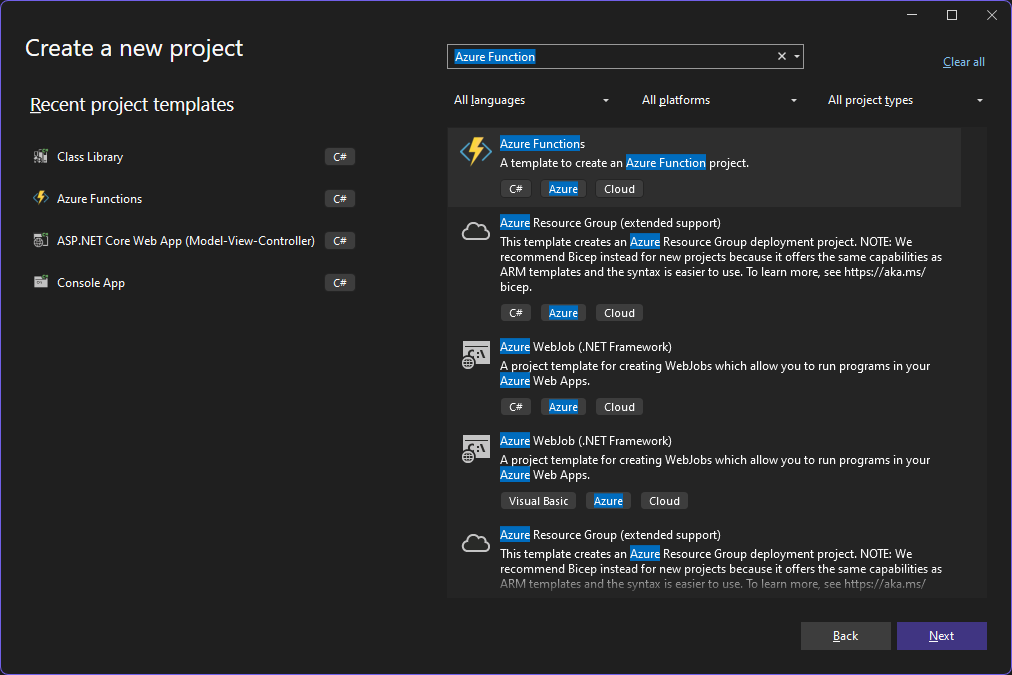
Give the project a name
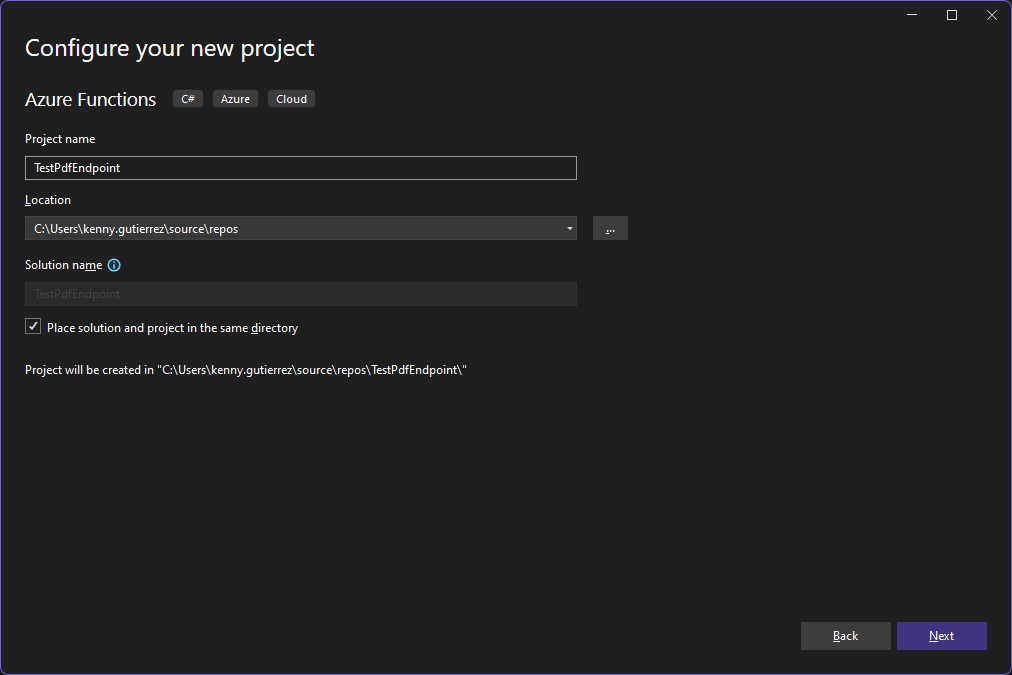
I'm taking the defaults here:
- .Net 8 Isolated for the version
- Http trigger for the function because we will be using GET and POST
- Enable container support because we will be utilizing Docker
- Function for the Authorization level so that it will require a Function Key. (When hosted in Azure at this authorization level it will require a Function Key to access the endpoint.)
Click Create.
This gives us the basic scaffolding.
using Microsoft.AspNetCore.Http;
using Microsoft.AspNetCore.Mvc;
using Microsoft.Azure.Functions.Worker;
using Microsoft.Extensions.Logging;
namespace TestPdfEndpoint
{
public class Function1
{
private readonly ILogger<Function1> _logger;
public Function1(ILogger<Function1> logger)
{
_logger = logger;
}
[Function("Function1")]
public IActionResult Run([HttpTrigger(AuthorizationLevel.Function, "get", "post")] HttpRequest req)
{
_logger.LogInformation("C# HTTP trigger function processed a request.");
return new OkObjectResult("Welcome to Azure Functions!");
}
}
}Add the ConvertUrlToPdf Function
Rename Function1 to ConvertUrlToPdf.
public class ConvertUrlToPdf
{
private readonly ILogger<ConvertUrlToPdf> _logger;
public ConvertUrlToPdf(ILogger<ConvertUrlToPdf> logger)
{
_logger = logger;
}
[Function("ConvertUrlToPdf")]
public IActionResult Run([HttpTrigger(AuthorizationLevel.Function, "get", "post")] HttpRequest req)
{
_logger.LogInformation("C# HTTP trigger function processed a request.");
return new OkObjectResult("Welcome to Azure Functions!");
}
}Change IActionResult to an async task and add a FunctionContext parameter.
public async Task<IActionResult> Run([HttpTrigger(AuthorizationLevel.Function, "get", "post")] HttpRequest req, FunctionContext functionContext)Add the Syncfusion.HtmlToPdfConverter.Net.Linux nuget package. Our Function App will be hosted on Linux. This package will do the heavy lifting of converting the URL to a PDF file. The nuget includes the Blink headless Chrome browser.
We will pass a URL to the function as a querystring parameter so check the request for a "URL" parameter. Return an EmptyResult if not found.
string urlString = req.Query["url"];
//return if no url
if (string.IsNullOrEmpty(urlString))
{
return new EmptyResult();
}Get the path to the Blink binaries. This will be needed later in a settings object:
var directory = Directory.GetCurrentDirectory();
var blinkBinariesPath = Path.Combine(directory, "runtimes/linux/native");Initialize the HTML to PDF Converter:
//Initialize the HTML to PDF converter with the Blink rendering engine.
var htmlConverter = new HtmlToPdfConverter(HtmlRenderingEngine.Blink)
{
ConverterSettings = null,
ReuseBrowserProcess = false
};Create a settings object and set the values. These command line argument settings come from the Syncfusion documentation.
var settings = new BlinkConverterSettings();
//Set command line arguments to run without sandbox.
settings.CommandLineArguments.Add("--no-sandbox");
settings.CommandLineArguments.Add("--disable-setuid-sandbox");
settings.BlinkPath = blinkBinariesPath;Assign the settings object.
//Assign WebKit settings to the HTML converter
htmlConverter.ConverterSettings = settings;Pass the URL to the converter. Save to an output stream.
var newDocument = htmlConverter.Convert(urlString);
var ms = new MemoryStream();
newDocument.Save(ms);
newDocument.Close();
ms.Position = 0;Return a FileStreamResult from the MemoryStream. Giving it a content type and a file name.
return new FileStreamResult(ms, "application/pdf")
{
FileDownloadName = "Test.pdf"
};At this point, your function should look like this:
public class ConvertUrlToPdf
{
private readonly ILogger<ConvertUrlToPdf> _logger;
public ConvertUrlToPdf(ILogger<ConvertUrlToPdf> logger)
{
_logger = logger;
}
[Function("ConvertUrlToPdf")]
public async Task<IActionResult> Run([HttpTrigger(AuthorizationLevel.Function, "get", "post")] HttpRequest req, FunctionContext functionContext)
{
string urlString = req.Query["url"];
//return if no url
if (string.IsNullOrEmpty(urlString))
{
return new EmptyResult();
}
var directory = Directory.GetCurrentDirectory();
var blinkBinariesPath = Path.Combine(directory, "runtimes/linux/native");
//Initialize the HTML to PDF converter with the Blink rendering engine.
var htmlConverter = new HtmlToPdfConverter(HtmlRenderingEngine.Blink)
{
ConverterSettings = null,
ReuseBrowserProcess = false
};
var settings = new BlinkConverterSettings();
//Set command line arguments to run without sandbox.
settings.CommandLineArguments.Add("--no-sandbox");
settings.CommandLineArguments.Add("--disable-setuid-sandbox");
settings.BlinkPath = blinkBinariesPath;
//Assign WebKit settings to the HTML converter
htmlConverter.ConverterSettings = settings;
var newDocument = htmlConverter.Convert(urlString);
var ms = new MemoryStream();
newDocument.Save(ms);
newDocument.Close();
ms.Position = 0;
return new FileStreamResult(ms, "application/pdf")
{
FileDownloadName = "Test.pdf"
};
}
}
You can add additional querystring parameters to control all aspects of the PDF output such as orientation, height, width, output file name, etc.
string orientation = req.Query["orientation"];
string widthString = req.Query["width"];
string heightString = req.Query["height"];
string fileName = req.Query["filename"];
int.TryParse(widthString, out int width);
int.TryParse(heightString, out var height);
if (width == 0)
{
width = 817;
}
if (!string.IsNullOrEmpty(orientation) && orientation.ToLower().Equals("landscape"))
settings.Orientation = PdfPageOrientation.Landscape;
settings.BlinkPath = blinkBinariesPath;
settings.Margin.All = 0;
settings.ViewPortSize = new Size(width, height);Updating the Dockerfile
There are some underlying requirements that Syncfusion needs in place so you'll need to add the following to your Dockerfile (refer to Syncfusion documentation):
RUN apt-get update && \
apt-get install -yq --no-install-recommends \
libasound2 libatk1.0-0 libc6 libcairo2 libcups2 libdbus-1-3 \
libexpat1 libfontconfig1 libgcc1 libgconf-2-4 libgdk-pixbuf2.0-0 libglib2.0-0 libgtk-3-0 libnspr4 \
libpango-1.0-0 libpangocairo-1.0-0 libstdc++6 libx11-6 libx11-xcb1 libxcb1 \
libxcursor1 libxdamage1 libxext6 libxfixes3 libxi6 libxrandr2 libxrender1 libxss1 libxtst6 \
libnss3 libgbm1So my complete Dockerfile looks as follows:
#See https://aka.ms/customizecontainer to learn how to customize your debug container and how Visual Studio uses this Dockerfile to build your images for faster debugging.
FROM mcr.microsoft.com/azure-functions/dotnet-isolated:4-dotnet-isolated8.0 AS base
RUN apt-get update && \
apt-get install -yq --no-install-recommends \
libasound2 libatk1.0-0 libc6 libcairo2 libcups2 libdbus-1-3 \
libexpat1 libfontconfig1 libgcc1 libgconf-2-4 libgdk-pixbuf2.0-0 libglib2.0-0 libgtk-3-0 libnspr4 \
libpango-1.0-0 libpangocairo-1.0-0 libstdc++6 libx11-6 libx11-xcb1 libxcb1 \
libxcursor1 libxdamage1 libxext6 libxfixes3 libxi6 libxrandr2 libxrender1 libxss1 libxtst6 \
libnss3 libgbm1
WORKDIR /home/site/wwwroot
EXPOSE 8080
FROM mcr.microsoft.com/dotnet/sdk:8.0 AS build
ARG BUILD_CONFIGURATION=Release
WORKDIR /src
COPY ["TestPdfEndpoint.csproj", "."]
RUN dotnet restore "./TestPdfEndpoint.csproj"
COPY . .
WORKDIR "/src/."
RUN dotnet build "./TestPdfEndpoint.csproj" -c $BUILD_CONFIGURATION -o /app/build
FROM build AS publish
ARG BUILD_CONFIGURATION=Release
RUN dotnet publish "./TestPdfEndpoint.csproj" -c $BUILD_CONFIGURATION -o /app/publish /p:UseAppHost=false
FROM base AS final
WORKDIR /home/site/wwwroot
COPY --from=publish /app/publish .
ENV AzureWebJobsScriptRoot=/home/site/wwwroot \
AzureFunctionsJobHost__Logging__Console__IsEnabled=trueTesting the PrintUrlToPdf Endpoint
Spin up the container using Docker Desktop. You can use your browser or Postman to test the PDF generation. Append the URL of the site you want to print to the querystring.
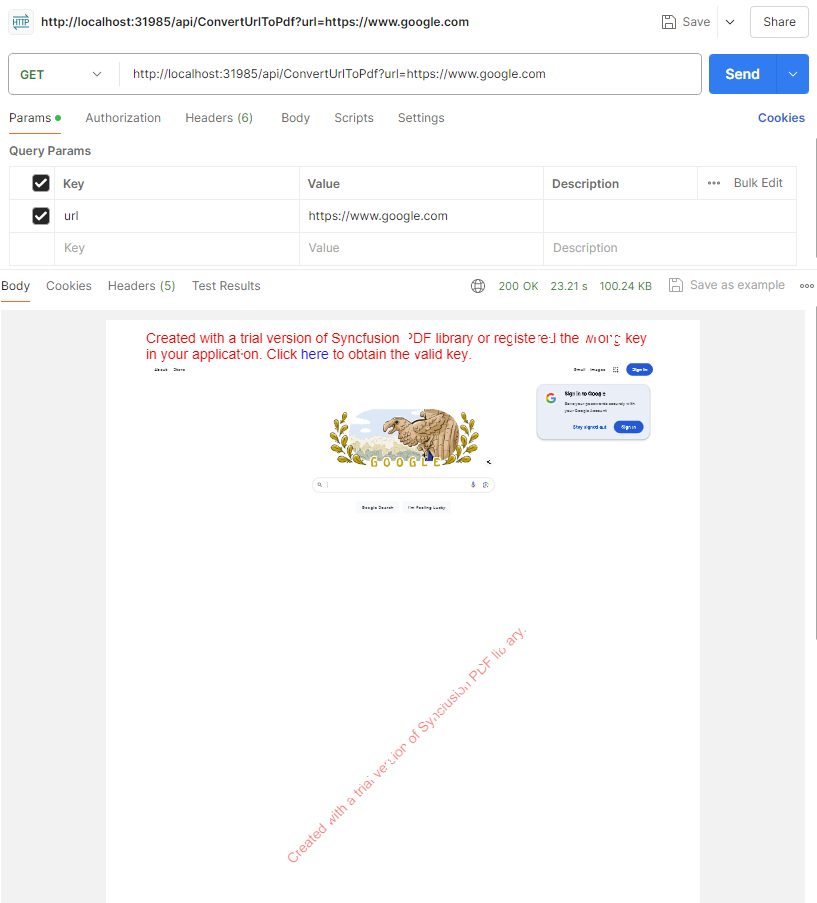
Add the ConvertToPdf Function
The second function is mostly a copy/paste of the first with some tweaks.
For this function, we'll look for an array of Xhtmlstrings that are POSTed.
req.Form.TryGetValue("html", out var strings);Then we'll create a stream for each one.
var streams = new Stream[strings.Count];
for (var i = 0; i < strings.Count; i++)
{
streams[i] = GetMemoryStream(strings[i], htmlConverter);
}GetMemoryStream looks like the following:
private static MemoryStream GetMemoryStream(string url, HtmlToPdfConverter htmlConverter)
{
try
{
PdfDocument newDocument = htmlConverter.Convert(url, string.Empty);
var ms = new MemoryStream();
newDocument.Save(ms);
newDocument.Close();
ms.Position = 0;
return ms;
}
catch (Exception e)
{
Console.WriteLine(e);
throw;
}
}Create a new PdfDocument that will hold the merged content.
var mergedDocument = new PdfDocument
{
EnableMemoryOptimization = true
};Add the streams into the PdfDocument.
PdfDocumentBase.Merge(mergedDocument, streams);
//Save the document into stream.
var stream = new MemoryStream();
mergedDocument.Save(stream);
//Close the document.
mergedDocument.Close(true);
//Disposes the streams.
foreach (var memStream in streams)
{
await memStream.DisposeAsync();
}
stream.Position = 0;Finally, return the FileStreamResult.
return new FileStreamResult(stream, "application/pdf")
{
FileDownloadName = "TestMergedPdf.pdf"
};The final version of ConvertToPdf is as follows:
public class ConvertToPdf
{
private readonly ILogger<ConvertToPdf> _logger;
public ConvertToPdf(ILogger<ConvertToPdf> logger)
{
_logger = logger;
}
[Function("ConvertToPdf")]
public async Task<IActionResult> Run([HttpTrigger(AuthorizationLevel.Function, "get", "post")] HttpRequest req)
{
req.Form.TryGetValue("html", out var strings);
var directory = Directory.GetCurrentDirectory();
var blinkBinariesPath = Path.Combine(directory, "runtimes/linux/native");
//Initialize the HTML to PDF converter with the Blink rendering engine.
var htmlConverter = new HtmlToPdfConverter(HtmlRenderingEngine.Blink)
{
ConverterSettings = null,
ReuseBrowserProcess = false
};
var settings = new BlinkConverterSettings();
//Set command line arguments to run without sandbox.
settings.CommandLineArguments.Add("--no-sandbox");
settings.CommandLineArguments.Add("--disable-setuid-sandbox");
settings.BlinkPath = blinkBinariesPath;
//Assign WebKit settings to the HTML converter
htmlConverter.ConverterSettings = settings;
var streams = new Stream[strings.Count];
for (var i = 0; i < strings.Count; i++)
{
streams[i] = GetMemoryStream(strings[i], htmlConverter);
}
var mergedDocument = new PdfDocument
{
EnableMemoryOptimization = true
};
try
{
PdfDocumentBase.Merge(mergedDocument, streams);
//Save the document into stream.
var stream = new MemoryStream();
mergedDocument.Save(stream);
//Close the document.
mergedDocument.Close(true);
//Disposes the streams.
foreach (var memStream in streams)
{
await memStream.DisposeAsync();
}
stream.Position = 0;
return new FileStreamResult(stream, "application/pdf")
{
FileDownloadName = "TestMergedPdf.pdf"
};
}
catch (Exception e)
{
Console.WriteLine(e);
throw;
}
}
private static MemoryStream GetMemoryStream(string url, HtmlToPdfConverter htmlConverter)
{
try
{
PdfDocument newDocument = htmlConverter.Convert(url, string.Empty);
var ms = new MemoryStream();
newDocument.Save(ms);
newDocument.Close();
ms.Position = 0;
return ms;
}
catch (Exception e)
{
Console.WriteLine(e);
throw;
}
}
}
Testing the ConvertToPdf Endpoint
Spin up the container using Docker Desktop. Use Postman to test. POST to the endpoint, providing multiple "HTML" Key-Value pairs. One per page of the PDF
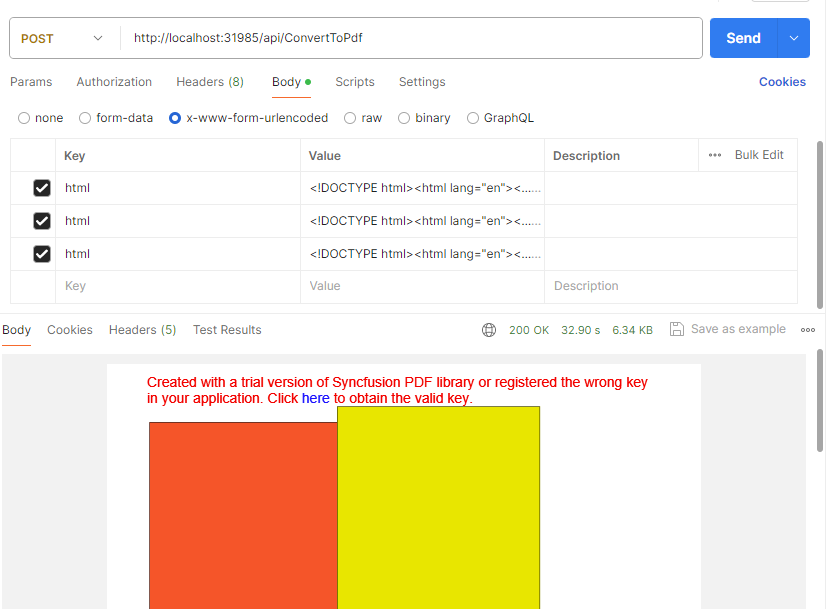
Tying it Back to your Optimizely Web App
Now that you have the endpoints, you can provide links to print specific URLs or POST content.
Notes
For production use, you will need to purchase a license and provide it to the app:
Syncfusion.Licensing.SyncfusionLicenseProvider.RegisterLicense("XXX...");Setting up the Function in Azure is outside of the scope of this article but I might cover it in a future post.
I really like what you've done here, it's technically very interesting. In an age where all browsers can print to PDF and you can use print stylesheets, it's very easy to dismiss this sort of solution, but it does still have a place.
This really comes into it's own when you have a very different HTML structure for printing compared to the structure you would use on website presentation. Perhaps you're aiming for a more professional looking PDF solution to contain the same content. There are entire components which don't have a place in the printed structure; Things like carousels need presenting differently, certain blocks may want removing, such as forms and signposting blocks, headers, footers etc.
The great thing about a function app is that it is not always on, it spins up fast and can cost next to nothing and allows your website to focus on serving content.
Mark I think you totally get it! Libraries like these let us custom-build the PDF exactly as we want it.
I wrote the article as a generic example but we are a homebuilder so we specifically use this to generate custom PDFs highlighting specific homes for sale in a given community. It's not the same view available on the front of the website.
In fact, there is logic within our Azure app that breaks the list of homes into individual pages making for a tidy multipage PDF that our sales team can share with buyers.
Sounds like the perfect example of when you should do this and why this is a great approach.