search
AI OnAI Off

Hi Dileep,
If your Wordpress blog has an RSS feed for blog posts, that would be ideal. You could then create a simple service that consumes the RSS feed and adds the items to your Episerver Find Index (see here: https://world.episerver.com/documentation/developer-guides/find/NET-Client-API/Indexing/ for examples of indexing objects). You could then create a scheduled job that runs periodically and uses your service to grab and index the Wordpress blog items. Hope this helps!
-John
Dileep,
Are you familiar with search connectors?
A search connector lets Episerver Find search content outside your website, such as an external blog related to your website. The connector lets your site visitors find the blog posts among your site's search results. For more, see http://webhelp.episerver.com/latest/en/find/adding-connectors.htm.
Dileep,
I don't know. Maybe a developer who has implemented this feature will respond.
Dileep
The crawled documents via search connectors are stored in find as a specific type "WebContent", you can verify this from Episerver Find UI. Assume if you only crawl from one external site, then you can use Find Filtering API to load external blog posts only.
One simple idea is to create a wordpress block and implement search rule in the blockcontroller.
I hope above helps.
Dileep
Even if the crawler exist there can be a lot of work to make it filter the info and not indexing the header and stuff like that.
So I would every day go for a solution where you either have an RSS feed or you build a custom API in Wordpress that you can talk to and then create a scheduled task in your site that imports the info and put it in Find. This gives you a lot of control.
Good luck!
From what I read from Find Connector documentation, it can support both Crawler and RSS/Atom type. I highly recommend you give a try with connector using RSS/Atom type, this might save you a few nights to crack API from scratch.
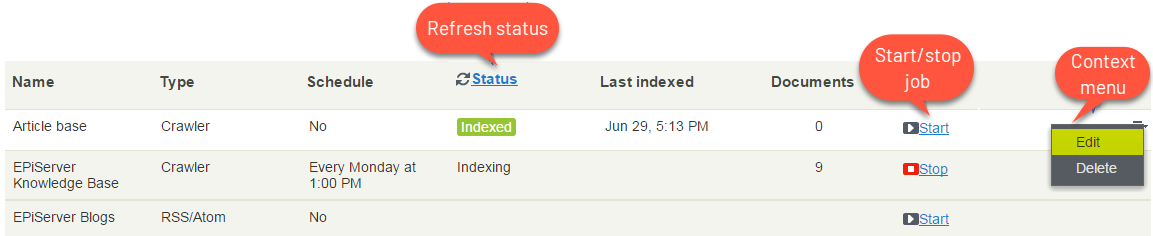
http://webhelp.episerver.com/latest/en/find/adding-connectors.htm




Hello,
I am not sure if this is possible.
I have a EpiServer website which uses Epi Find for search feature. I have another word press site for blogs. Now there is an ask if we could integrate wordpress to Episerver such that we can have the blogs searchable from Epi Find.
Please let me know if any questions.
Thanks.