
Import assets in bulk and create respective pages in Episerver CMS
Hello Guys,
Recently I came across one of the requirement to import PDF documents from external drive and create respective publication pages in Episerver. I have divided this requirement into below tasks:
- Import all PDF's into Episerver in same structure as it is in external drive
- Create episerver page for each PDF in same structure
To start with I have created two properties in setting page 1. Reference folder in Asset under which all PDF's will get imported and 2. Container page under which all publication pages will get created.
After creating properties, I have created admin tool to Import PDF. Below is logic to add in import service.
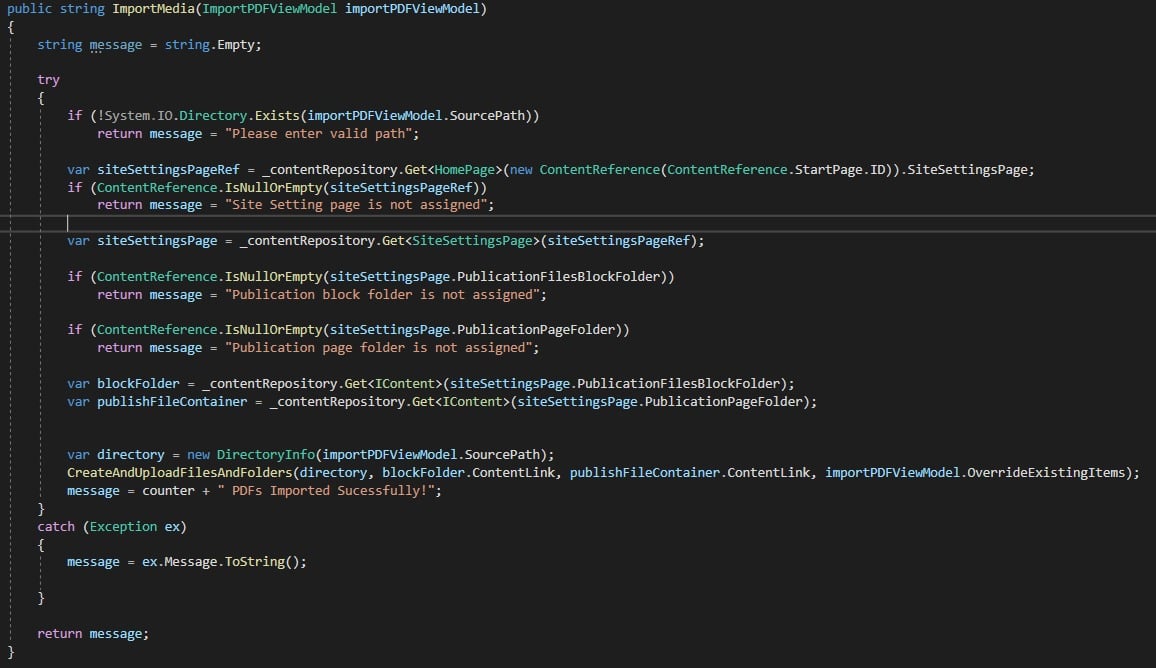
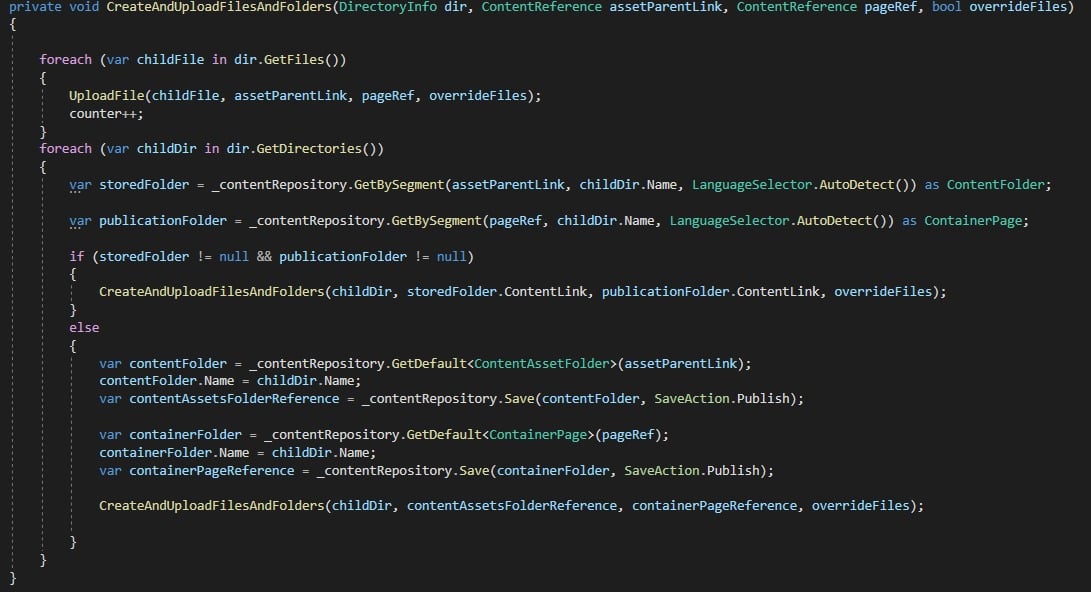
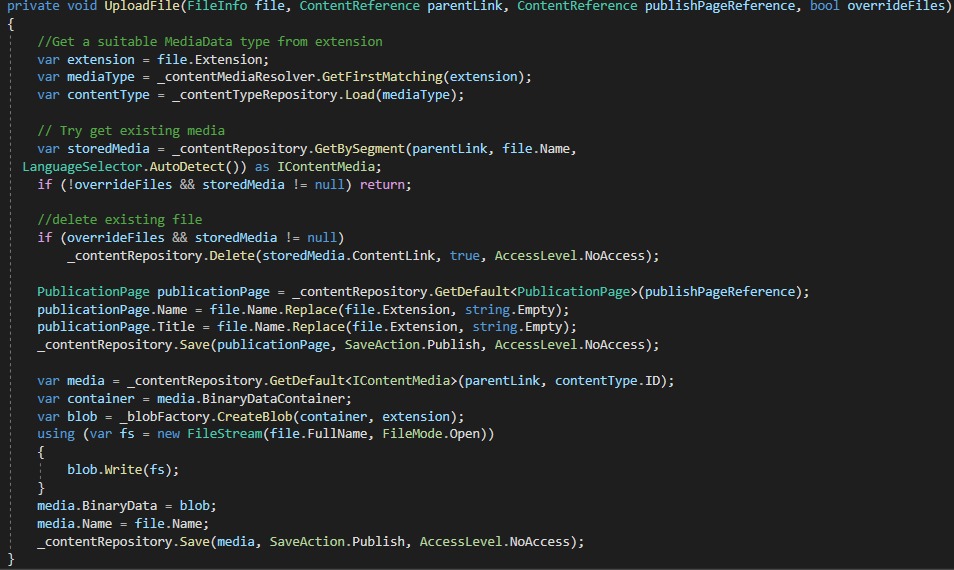
I still have to extend this feature to copy content from PDF to Publication pages. I will be using iText7 library for extension. Below is sample code for reading PDF's.
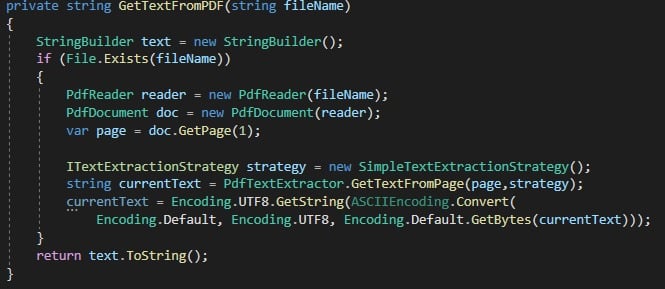
I have used below article as inspiration!
https://blog.nicolaayan.com/2017/03/episerver-how-to-upload-media-assets-in-bulk/
This functionality is very useful while migration of data. We can also extend this feature for various types of documents like PDF, Doc etc.
Thank you!
Hi Sameer, thank you for your contribution. It would be nice if you can share the code with us to reduce typo when apply your finding. The editor supports insert code with formatting like C#, PHP, Javascript, etc.
Hi Sam,
It is great article 👍, I have one query related to pdf read functionality, reading text from file is bit easier to achieve but what if the pdf has a scanned image, then how do you handle that?
Have came across any such situations during above implementation?
I mean,how you make sure that all pdf you are reading having readable text or it has a scanned image.
Thanks,
Chan
Hi Chan!
Thank you Chan!
Yes, above PDF file component will work to extract content from scanned PDF also. It extract all content even from scanned PDF copies!
//Sameer