AI OnAI Off
How to get occurences of a word from page in CMS


Hi Priyanka,
What do you mean about "not getting the right results through it"? ExtractTextFromContent method does not return all text for counting or the text content is correct as your expectation but counting incorrectly?
I saw that the ExtractTextFromContent method only return content of property string, not XhtmlString. I think you can use the extension method contentData .SearchText() from EPiServer.Find package to get all text in content data instead of using ExtractTextFromContent
Jun 20, 2024 10:23
Yes, the ExtractTextFromContent method does not return all text right now, it is checking only string properties. I need a method which can help me get all the text from contentData.
I tried contentData.SearchText(), but it is not returning all text data right now. For eg. if the page has a block and text fields inside the block, that text is not returned.
Jun 21, 2024 11:46
Hi Priyanka,
I think you may want to do Find search - not only for counting occurences for all text including text in Content Area as well right?
If it is true then you can index content in Content Area as well by adding IndexInContentAreas attribute at content type class level as following:
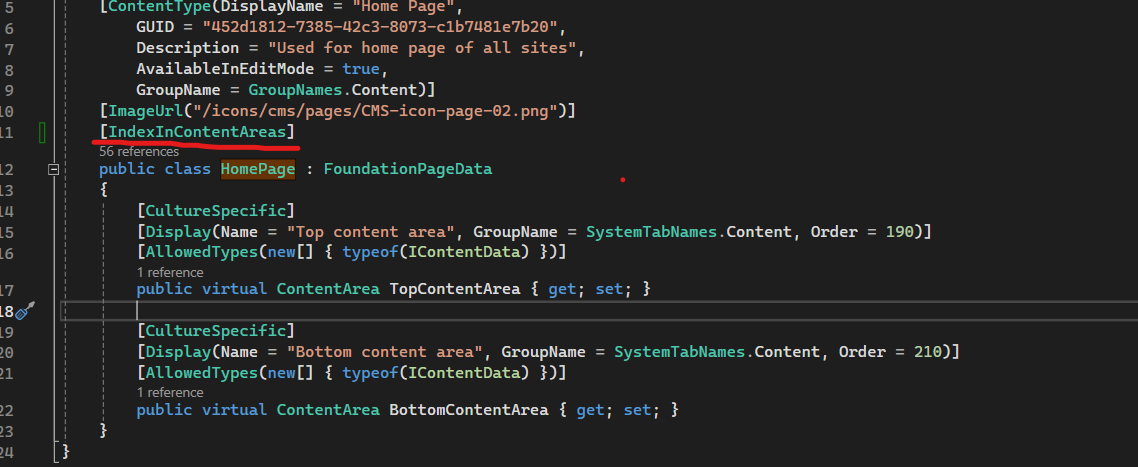
By this way, you could search content for all text including content area and could use SearchText method to count occurences as your expectation
Jun 21, 2024 12:31
I need to sort the search results based on the occurrence of the keyword. Once we get the result from executing the query, the idea is to get the occurence from the content of the results hits, and then sort results on that basis. I am using below functions to count the occurence, but not getting the right results through it. Has anybody been able to achieve similar functionality?
We are using Find 16.0.1
private int CountTermOccurrences(SearchHit<UnifiedSearchHit> hit, string searchTerm)
{
// Extract the text content to search for term occurrences
string contentText = ExtractTextFromContent(hit);
if (string.IsNullOrEmpty(contentText))
{
return 0;
}
// Count occurrences of the search term
int count = 0;
int index = contentText.IndexOf(searchTerm, 0, System.StringComparison.OrdinalIgnoreCase);
while (index != -1)
{
count++;
index = contentText.IndexOf(searchTerm, index + searchTerm.Length, System.StringComparison.OrdinalIgnoreCase);
}
return count;
}
private string ExtractTextFromContent(SearchHit<UnifiedSearchHit> hit)
{
var content = SearchHelper.GetOriginalObject(hit.Document);
// Extract text from different properties of the content (e.g., main body, summary, etc.)
// Customize this method to fit your content model
var contentData = content as IContentData;
var textProperties = new List<string>();
if (contentData != null)
{
foreach (var property in contentData.Property)
{
if (property.PropertyValueType == typeof(string))
{
textProperties.Add(property.Value as string);
}
}
}
return string.Join(" ", textProperties);
}